
System Architecture#
In this section, we will lay out the overall system architecture for Modin, as well as go into detail about the component design, implementation and other important details. This document also contains important reference information for those interested in contributing new functionality, bugfixes and enhancements.
High-Level Architectural View#
The diagram below outlines the general layered view to the components of Modin with a short description of each major section of the documentation following.

Modin is logically separated into different layers that represent the hierarchy of a typical Database Management System. Abstracting out each component allows us to individually optimize and swap out components without affecting the rest of the system. We can implement, for example, new compute kernels that are optimized for a certain type of data and can simply plug it in to the existing infrastructure by implementing a small interface. It can still be distributed by our choice of compute engine with the logic internally.
System View#
A top-down view of Modin’s architecture is detailed below:
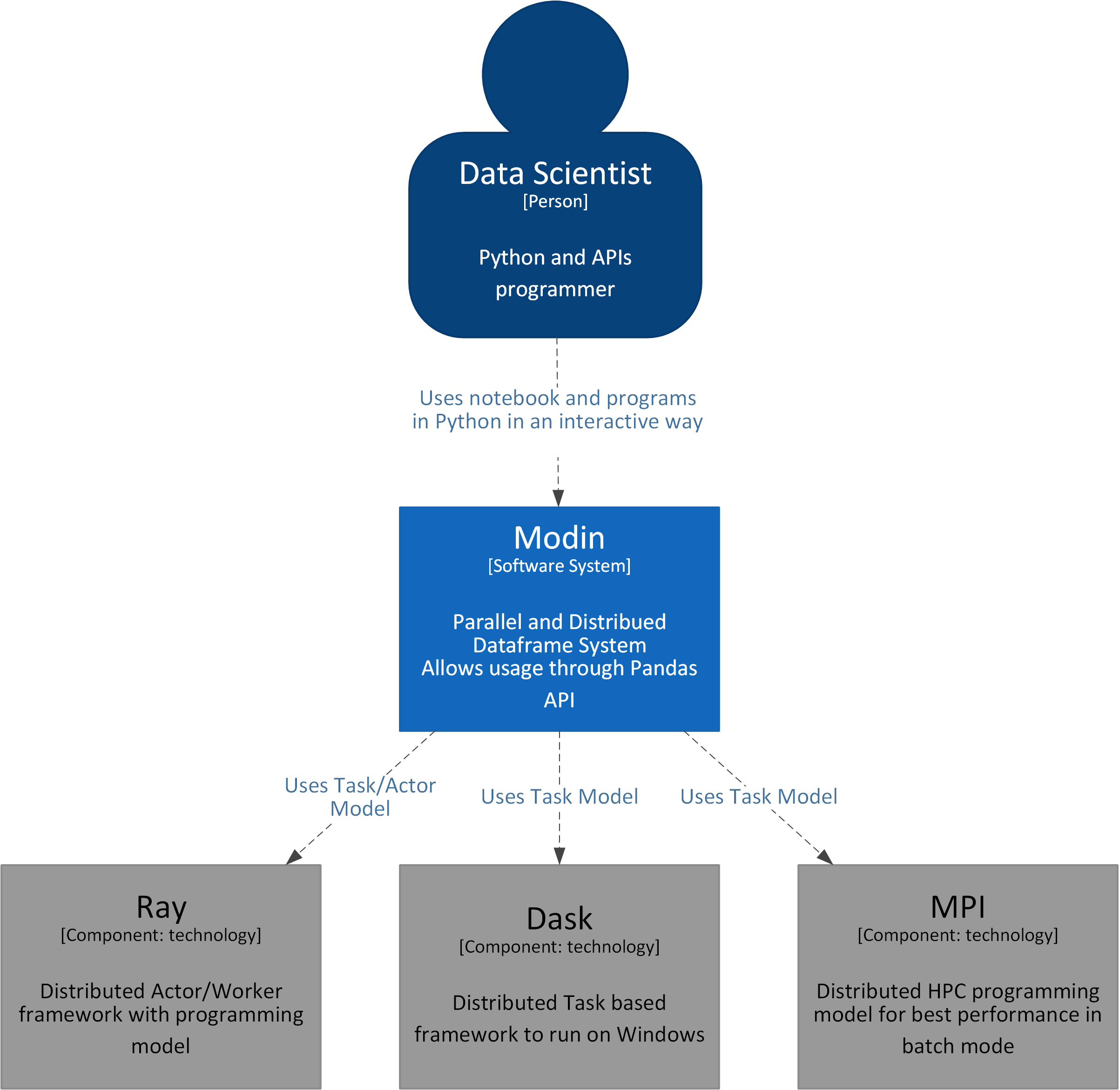
The user - Data Scientist interacts with the Modin system by sending interactive or batch commands through API and Modin executes them using various execution engines: Ray, Dask and MPI are currently supported.
Subsystem/Container View#
If we click down to the next level of details we will see that inside Modin the layered architecture is implemented using several interacting components:
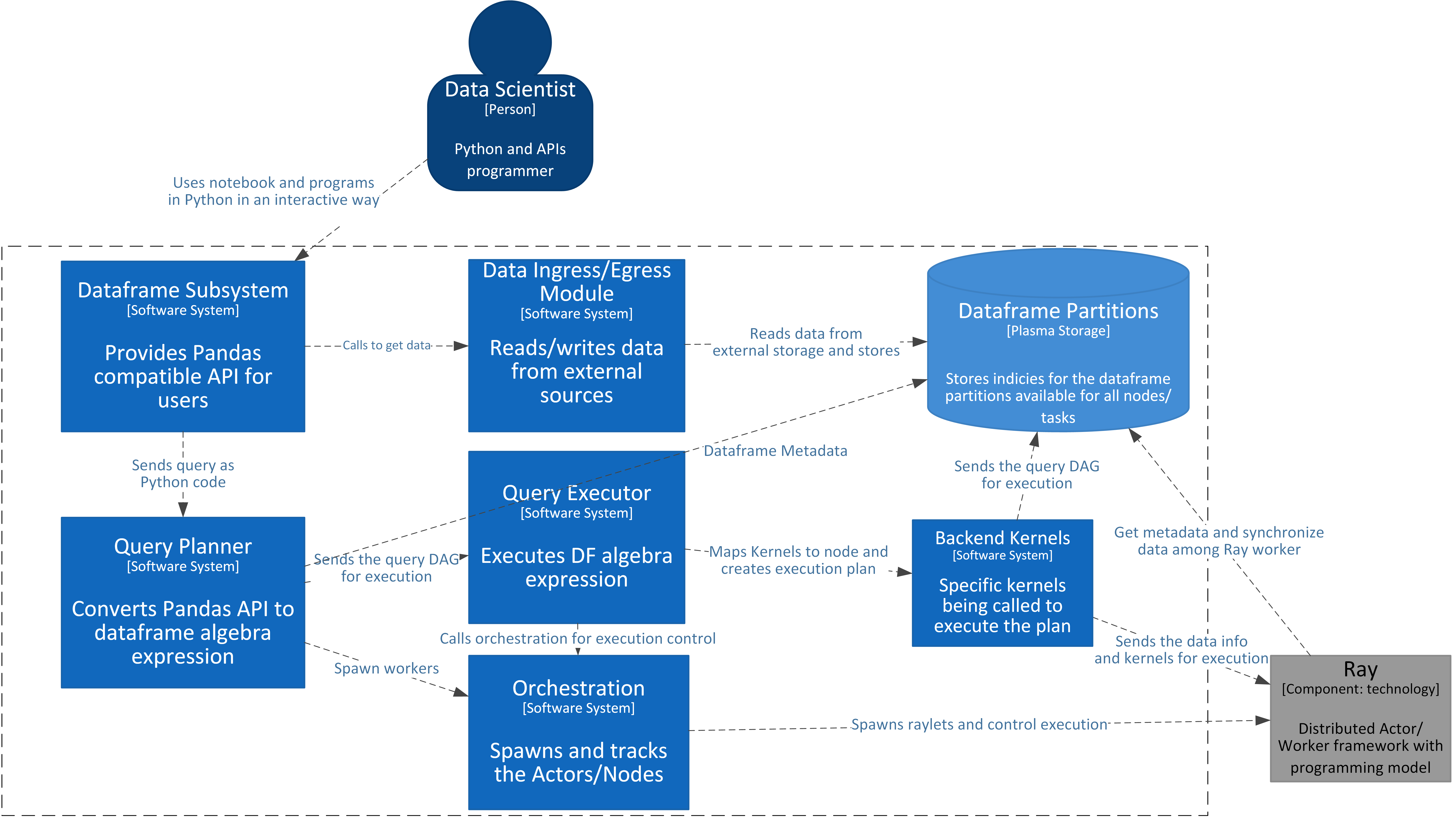
For the simplicity the other execution systems - Dask and MPI are omitted and only Ray execution is shown.
Dataframe subsystem is the backbone of the dataframe holding and query compilation. It is responsible for dispatching the ingress/egress to the appropriate module, getting the pandas API and calling the query compiler to convert calls to the internal intermediate Dataframe Algebra.
Data Ingress/Egress Module is working in conjunction with Dataframe and Partitions subsystem to read data split into partitions and send data into the appropriate node for storing.
Query Planner is subsystem that translates the pandas API to intermediate Dataframe Algebra representation DAG and performs an initial set of optimizations.
Query Executor is responsible for getting the Dataframe Algebra DAG, performing further optimizations based on a selected storage format and mapping or compiling the Dataframe Algebra DAG to and actual execution sequence.
Storage formats module is responsible for mapping the abstract operation to an actual executor call, e.g. pandas, custom format.
Orchestration subsystem is responsible for spawning and controlling the actual execution environment for the selected execution. It spawns the actual nodes, fires up the execution environment, e.g. Ray, monitors the state of executors and provides telemetry
Component View#
User queries which perform data transformation, data ingress or data egress pass through the Modin components detailed below. The path the query takes is mostly similar across execution systems.
Data Transformation#

Query Compiler#
The Query Compiler receives queries from the pandas API layer. The API layer is responsible for ensuring a clean input to the Query Compiler. The Query Compiler must have knowledge of the compute kernels and in-memory format of the data in order to efficiently compile the query.
The Query Compiler is responsible for sending the compiled query to the Core Modin Dataframe. In this design, the Query Compiler does not have information about where or when the query will be executed, and gives the control of the partition layout to the Modin Dataframe.
In the interest of reducing the pandas API, the Query Compiler layer closely follows the pandas API, but cuts out a large majority of the repetition.
Automatic Engine Switching and Casting#
QueryCompilers which are derived from QueryCompilerCaster can participate in automatic casting when different query compilers, representing different underlying engines, are used together in a function. A relative “cost” of casting is used to determine which query compiler everything should be moved to. Each query compiler must implement the functions, move_to_cost, move_to_me_cost, max_cost and stay_cost to provide information and query costs associated with different decision points in cost opimization. With the exception of max_cost these methods need to return a QCCoercionCost in the range of 0-1000.
These functions have precise meanings:
move_to_cost is the transmission cost of moving the data, including known serialization costs from the perspective of that particular compiler. Colloquially, the question being asked of the query compiler is, “What is the normalized cost of moving my data to the other engine?”
move_to_me_cost is the execution cost for the data and operation on the proposed destination query compiler. Since this method is called before the data has been migrated this is a class method and the destination query_compiler may have very limited information on the possible cost after migration. Factors that may be considered here include available memory, cpu, and the unique characteristics of the engine. The question being asked is, “If this data were moved to me, what would be the normalized execution cost to perform that operation?”
stay_cost is the execution cost on the current query compilier ( where the data is ). The question asked of the query compiler is, “If I were to keep this data on my engine, what would be the normalized execution cost?”
max_cost is the maximum cost allowed by this query compiler across all data movements. This method sets a normalized upper bound for situations where multiple data frames from different engines all need to move to the same engine. The value returned by this method can exceed QCCoercionCost.COST_IMPOSSIBLE
There are generally two places where automatic casting is considered: When two or more DataFrames on different engines are participating in an operation ( such as pd.concat ) or at registered functions for particular engines through the register_function_for_pre_op_switch and register_function_for_post_op_switch methods.
Core Modin Dataframe#
At this layer, operations can be performed lazily. Currently, Modin executes most
operations eagerly in an attempt to behave as pandas does. Some operations, e.g.
transpose are expensive and create full copies of the data in-memory. In these
cases, we can wait until another operation triggers computation. In the future, we plan
to add additional query planning and laziness to Modin to ensure that queries are
performed efficiently.
The structure of the Core Modin Dataframe is extensible, such that any operation that could be better optimized for a given execution can be overridden and optimized in that way.
This layer has a significantly reduced API from the QueryCompiler and the user-facing API. Each of these APIs represents a single way of performing a given operation or behavior.
Core Modin Dataframe API#
More documentation can be found internally in the code. This API is not complete, but represents an overwhelming majority of operations and behaviors.
This API can be implemented by other distributed/parallel DataFrame libraries and plugged in to Modin as well. Create an issue or discuss on our Slack for more information!
The Core Modin Dataframe is responsible for the data layout and shuffling, partitioning, and serializing the tasks that get sent to each partition. Other implementations of the Modin Dataframe interface will have to handle these as well.
Partition Manager#
The Partition Manager can change the size and shape of the partitions based on the type of operation. For example, certain operations are complex and require access to an entire column or row. The Partition Manager can convert the block partitions to row partitions or column partitions. This gives Modin the flexibility to perform operations that are difficult in row-only or column-only partitioning schemas.
Another important component of the Partition Manager is the serialization and shipment
of compiled queries to the Partitions. It maintains metadata for the length and width of
each partition, so when operations only need to operate on or extract a subset of the
data, it can ship those queries directly to the correct partition. This is particularly
important for some operations in pandas which can accept different arguments and
operations for different columns, e.g. fillna with a dictionary.
This abstraction separates the actual data movement and function application from the Dataframe layer to keep the Core Dataframe API small and separately optimize the data movement and metadata management.
Partitions#
Partitions are responsible for managing a subset of the Dataframe. As mentioned below, the Dataframe is partitioned both row and column-wise. This gives Modin scalability in both directions and flexibility in data layout. There are a number of optimizations in Modin that are implemented in the partitions. Partitions are specific to the execution framework and in-memory format of the data, allowing Modin to exploit potential optimizations across both. These optimizations are explained further on the pages specific to the execution framework.
Execution Engine#
This layer performs computation on partitions of the data. The Modin Dataframe is designed to work with task parallel frameworks, but integration with data parallel frameworks should be possible with some effort.
Storage Format#
The storage format describes the in-memory partition type.
The base storage format in Modin is pandas. In the default case, the Modin Dataframe operates on partitions that contain pandas.DataFrame objects.
Data Ingress#
Note
Data ingress operations (e.g. read_csv) in Modin load data from the source into
partitions and vice versa for data egress (e.g. to_csv) operation.
Improved performance is achieved by reading/writing in partitions in parallel.
Data ingress starts with a function in the pandas API layer (e.g. read_csv). Then the user’s
query is passed to the Factory Dispatcher,
which defines a factory specific for the execution. The factory for execution contains an IO class
(e.g. PandasOnRayIO) whose responsibility is to perform a parallel read/write from/to a file.
This IO class contains class methods with interfaces and names that are similar to pandas IO functions
(e.g. PandasOnRayIO.read_csv). The IO class declares the Modin Dataframe and Query Compiler
classes specific for the execution engine and storage format to ensure the correct object is constructed.
It also declares IO methods that are mix-ins containing a combination of the engine-specific class for
deploying remote tasks, the class for parsing the given file format and the class handling the chunking
of the format-specific file on the head node (see dispatcher classes implementation
details). The output from the IO class data ingress function is
a Modin Dataframe.

Data Egress#
Data egress operations (e.g. to_csv) are similar to data ingress operations up to
execution-specific IO class functions construction. Data egress functions of the IO class
are defined slightly different from data ingress functions and created only
specifically for the engine since partitions already have information about its storage
format. Using the IO class, data is exported from partitions to the target file.

Supported Execution Engines and Storage Formats#
This is a list of execution engines and in-memory formats supported in Modin. If you would like to contribute a new execution engine or in-memory format, please see the documentation page on contributing.
- pandas on Ray
Uses the Ray execution framework.
The storage format is pandas and the in-memory partition type is a pandas DataFrame.
For more information on the execution path, see the pandas on Ray page.
- pandas on Dask
Uses the Dask Futures execution framework.
The storage format is pandas and the in-memory partition type is a pandas DataFrame.
For more information on the execution path, see the pandas on Dask page.
- pandas on MPI
The storage format is pandas and the in-memory partition type is a pandas DataFrame.
For more information on the execution path, see the pandas on Unidist page.
- pandas on Python
Uses native python execution - mainly used for debugging.
The storage format is pandas and the in-memory partition type is a pandas DataFrame.
For more information on the execution path, see the pandas on Python page.
- pandas on Snowflake
Uses the Snowpark Python library to transpile pandas API calls to SQL queries.
The storage format is the custom-defined Snowflake format; data remains within Snowflake warehouses until retrieved by pandas API calls.
For more information on pandas on Snowflake, refer to Snowflake’s documentation (external link).
DataFrame Partitioning#
The Modin DataFrame architecture follows in the footsteps of modern architectures for database and high performance matrix systems. We chose a partitioning schema that partitions along both columns and rows because it gives Modin flexibility and scalability in both the number of columns and the number of rows. The following figure illustrates this concept.
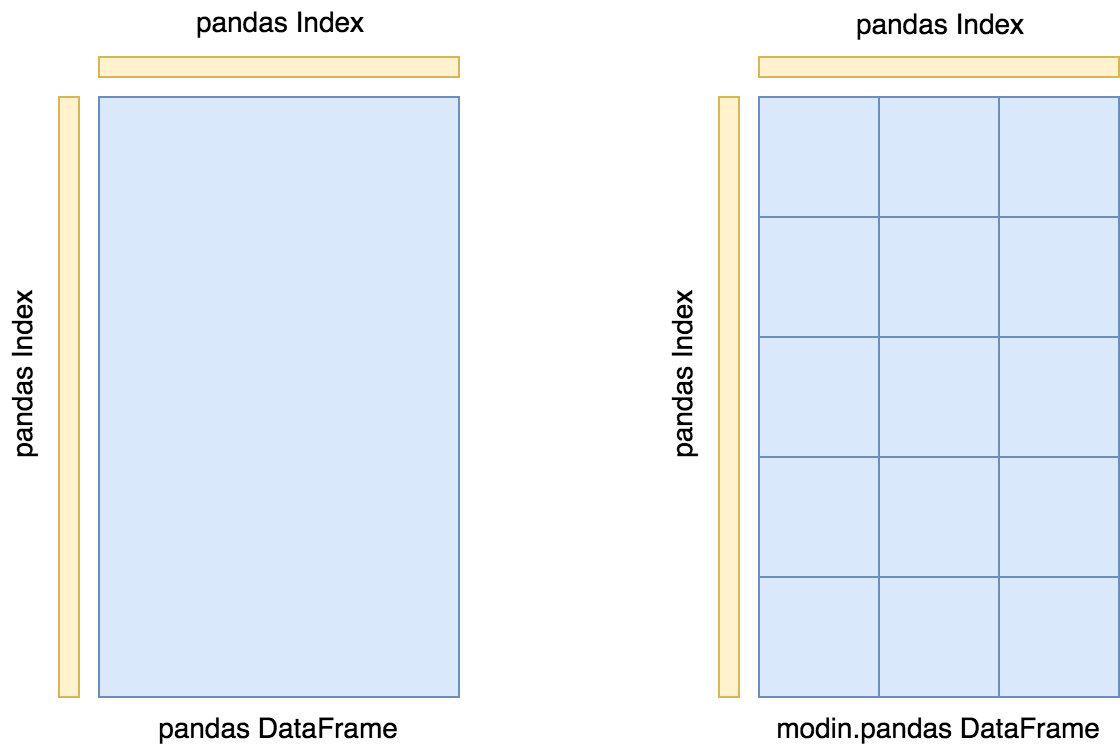
Currently, the main in-memory format of each partition is a pandas DataFrame (pandas storage format).
Index#
We currently use the pandas.Index object for indexing both columns and rows. In the
future, we will implement a distributed, pandas-compatible Index object in order to remove
this scaling limitation from the system. Most workloads will not be affected by this scalability limit
since it only appears when operating on more than 10’s of billions of columns or rows.
Important note: If you are using the
default index (pandas.RangeIndex) there is a fixed memory overhead (~200 bytes) and
there will be no scalability issues with the index.
API#
The API is the outer-most layer that faces users. The following classes contain Modin’s implementation of the pandas API:
Module/Class View#
Modin’s modules layout is shown below. Click on the links to deep dive into Modin’s internal implementation details. The documentation covers most modules, with more docs being added everyday!
├───.github ├───asv_bench ├───ci ├───docker ├───docs ├───examples ├───modin │ ├─── config | ├─── utils │ ├───core │ │ ├─── dataframe │ │ │ ├─── algebra │ │ │ ├─── base │ │ │ └─── pandas │ │ ├───execution │ │ │ ├───dask │ │ │ │ ├───common │ │ │ │ └───implementations │ │ │ │ └─── pandas_on_dask │ │ │ ├─── dispatching │ │ │ ├───python │ │ │ │ └───implementations │ │ │ │ └─── pandas_on_python │ │ │ ├───ray │ │ │ │ ├───common │ │ │ │ ├─── generic │ │ │ │ └───implementations │ │ │ │ └─── pandas_on_ray │ │ │ └───unidist │ │ │ ├───common │ │ │ ├─── generic │ │ │ └───implementations │ │ │ └─── pandas_on_unidist │ │ ├─── io │ │ └─── storage_formats │ │ ├─── base │ │ └─── pandas │ ├───distributed │ │ ├───dataframe │ │ │ └─── pandas │ ├─── experimental │ │ ├───core | | | └─── io │ │ ├─── pandas │ │ ├─── sklearn │ │ ├───spreadsheet │ │ ├─── xgboost │ │ └─── batch │ └───pandas │ ├─── dataframe │ └─── series ├───requirements ├───scripts └───stress_tests