
Advanced Usage#
Modin aims to not only optimize pandas, but also provide a comprehensive, integrated toolkit for data scientists. We are actively developing data science tools such as DataFrame spreadsheet integration, DataFrame algebra, progress bars, SQL queries on DataFrames, and more. Join us on Slack for the latest updates!
Modin engines#
Modin supports a series of execution engines such as Ray, Dask, MPI through unidist, each of which might be a more beneficial choice for a specific scenario. When doing the first operation with Modin it automatically initializes one of the engines to further perform distributed/parallel computation. If you are familiar with a concrete execution engine, it is possible to initialize the engine on your own and Modin will automatically attach to it. Refer to Modin engines page for more details.
Additional APIs#
Modin also supports these additional APIs on top of pandas to improve user experience.
to_pandas()– convert a Modin DataFrame/Series to a pandas DataFrame/Series.get_backend()– Get theBackendconfiguration variable of thisDataFrame.move_to()– Move data and execution for thisDataFrameto the givenBackendconfiguration variable. This method is an alias forDataFrame.set_backend.set_backend()– Move data and execution for thisDataFrameto the givenBackendconfiguration variable. This method is an alias forDatFrame.move_to.from_pandas()– convert a pandas DataFrame to a Modin DataFrame.to_ray()– convert a Modin DataFrame/Series to a Ray Dataset.from_ray()– convert a Ray Dataset to a Modin DataFrame.to_dask()– convert a Modin DataFrame/Series to a Ray Dataset.from_dask()– convert a Modin DataFrame/Series to a Dask DataFrame/Series.from_map()– create a Modin DataFrame from map function applied to an iterable object.from_arrow()– convert an Arrow Table to a Modin DataFrame.read_csv_glob()– read multiple files in a directory.read_sql()– add optional parameters for the database connection.read_custom_text()– read custom text data from file.read_pickle_glob()– read multiple pickle files in a directory.read_parquet_glob()– read multiple parquet files in a directory.read_json_glob()– read multiple json files in a directory.read_xml_glob()– read multiple xml files in a directory.to_pickle_glob()– write to multiple pickle files in a directory.to_parquet_glob()– write to multiple parquet files in a directory.to_json_glob()– write to multiple json files in a directory.to_xml_glob()– write to multiple xml files in a directory.
DataFrame partitioning API#
Modin DataFrame provides an API to directly access partitions: you can extract physical partitions from
a DataFrame, modify their structure by reshuffling or applying some
functions, and create a DataFrame from those modified partitions. Visit
pandas partitioning API documentation to learn more.
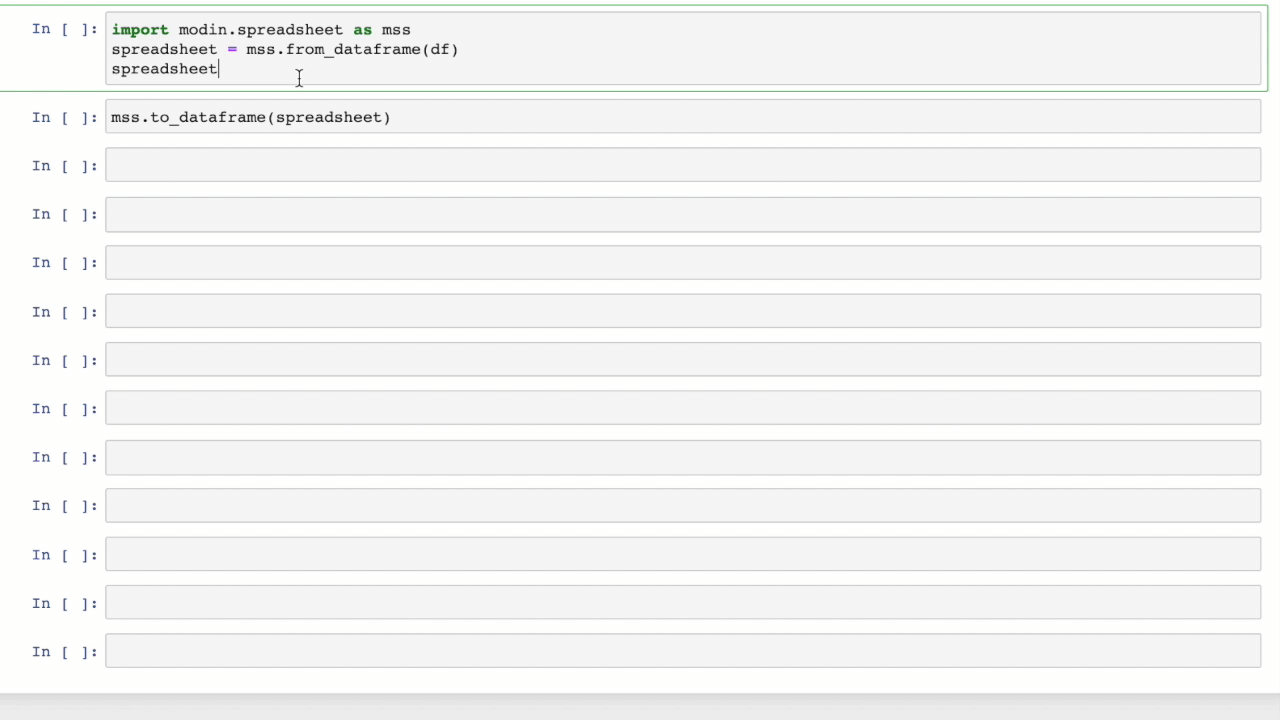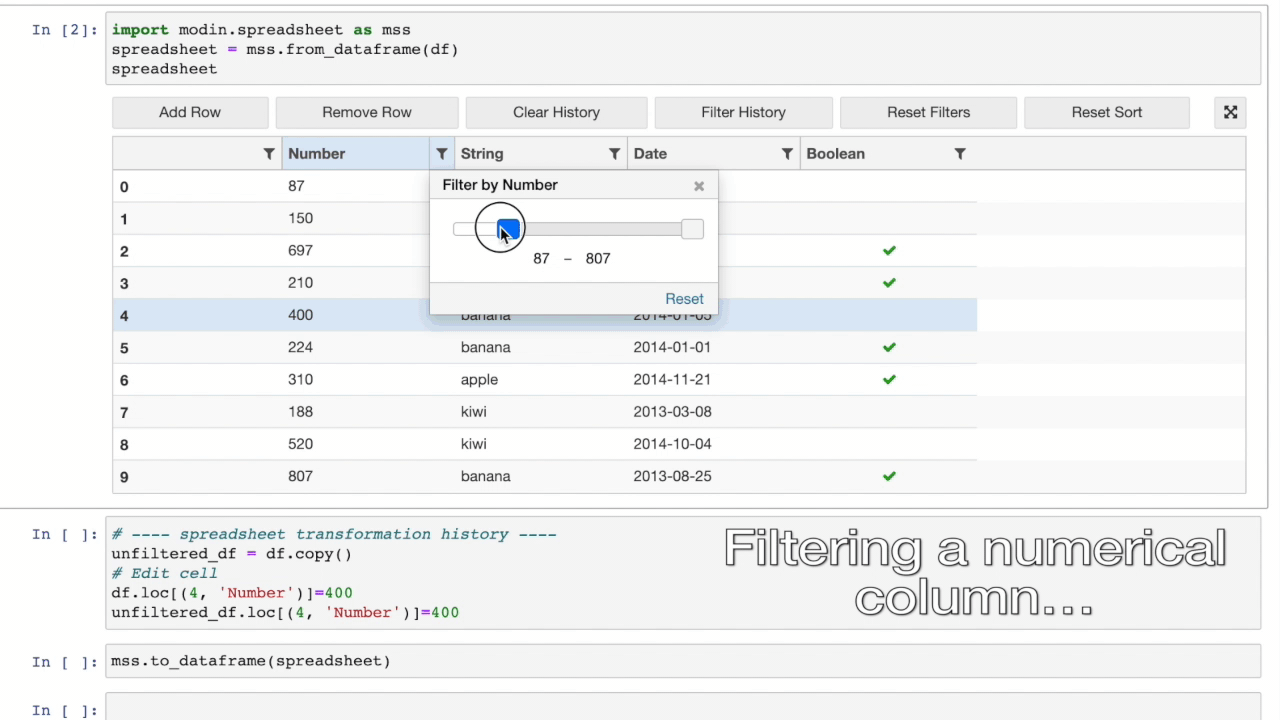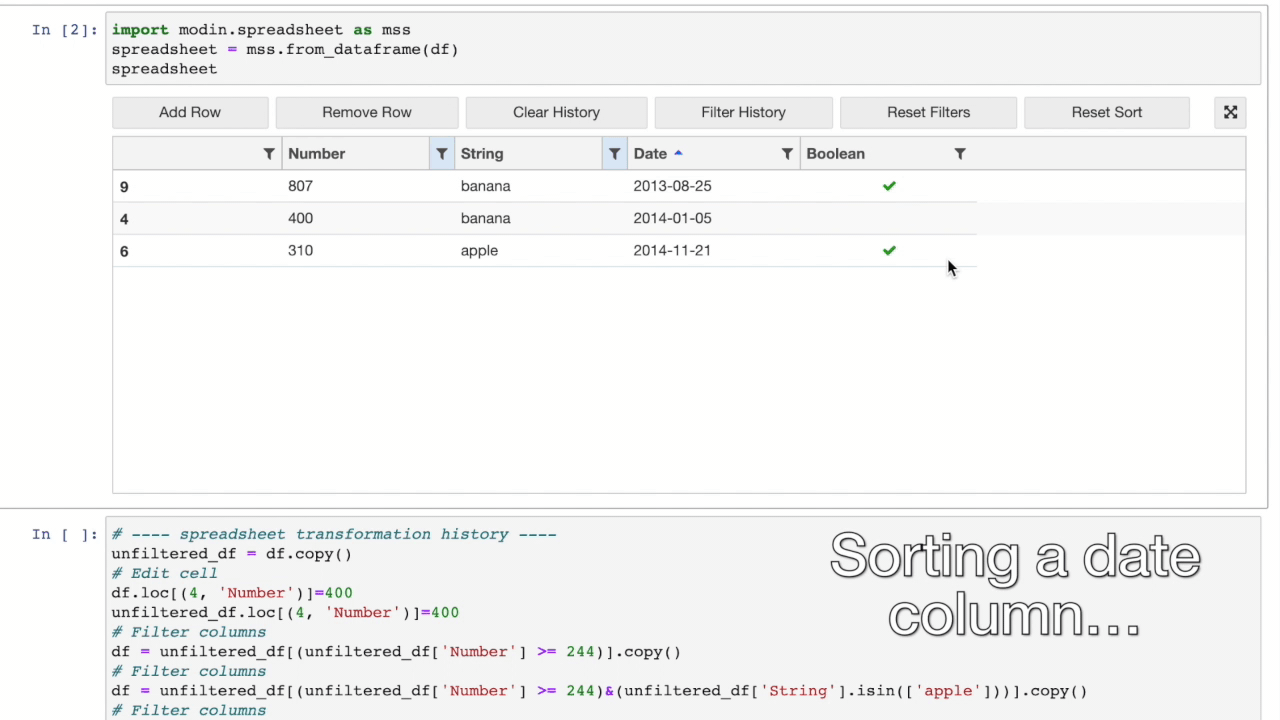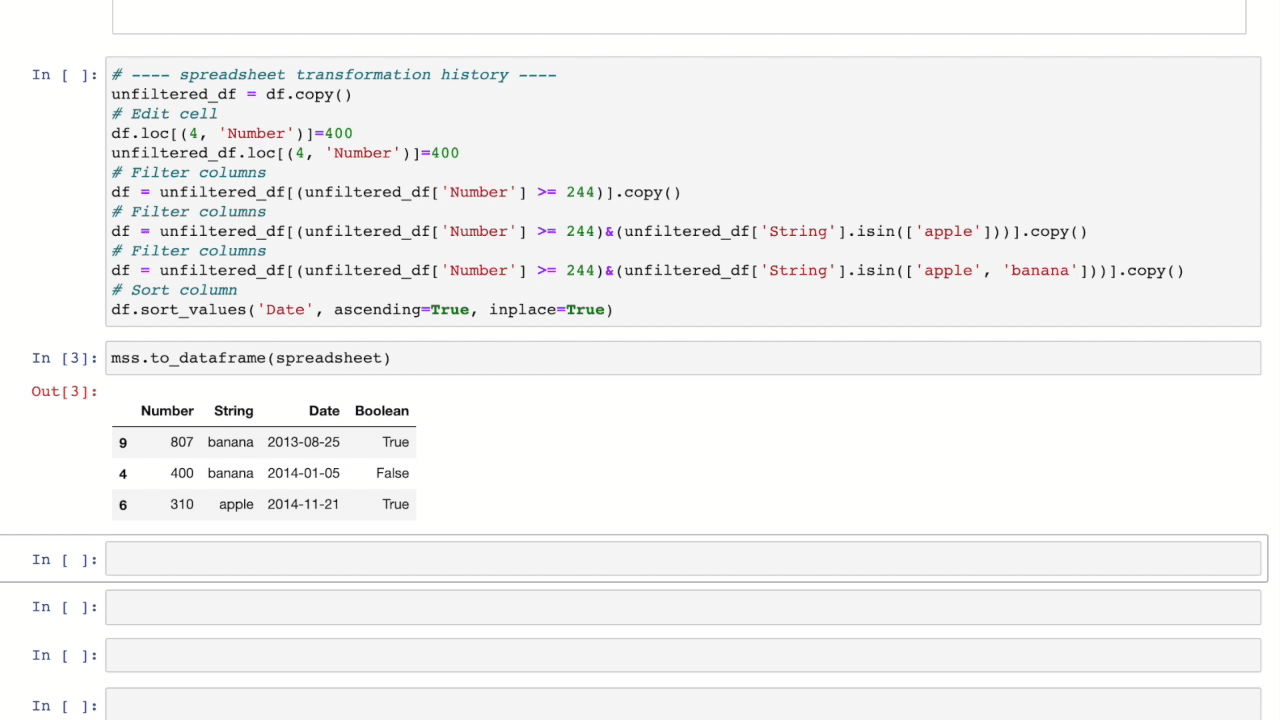
Modin Spreadsheet API#
The Spreadsheet API for Modin allows you to render the dataframe as a spreadsheet to easily explore your data and perform operations on a graphical user interface. The API also includes features for recording the changes made to the dataframe and exporting them as reproducible code. Built on top of Modin and SlickGrid, the spreadsheet interface is able to provide interactive response times even at a scale of billions of rows. See our Modin Spreadsheet API documentation for more details.
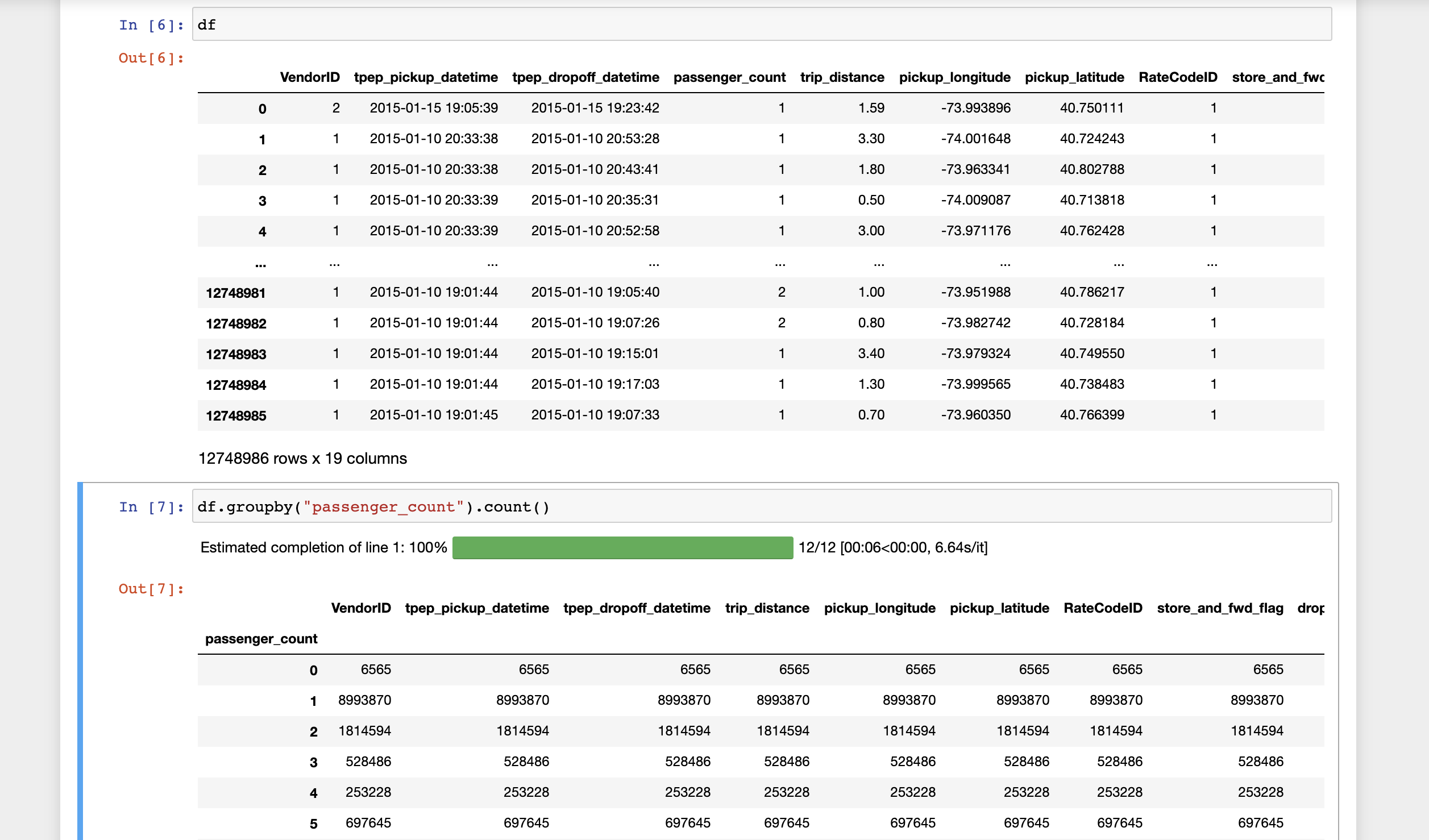
Progress Bar#
Visual progress bar for Dataframe operations such as groupby and fillna, as well as for file reading operations such as read_csv. Built using the tqdm library and Ray execution engine. See Progress Bar documentation for more details.
Dataframe Algebra#
A minimal set of operators that can be composed to express any dataframe query for use in query planning and optimization. See our paper for more information, and full documentation is coming soon!
Distributed XGBoost on Modin#
Modin provides an implementation of distributed XGBoost machine learning algorithm on Modin DataFrames. See our Distributed XGBoost on Modin documentation for details about installation and usage, as well as Modin XGBoost architecture documentation for information about implementation and internal execution flow.
Logging with Modin#
Modin logging offers users greater insight into their queries by logging internal Modin API calls, partition metadata, and system memory. Logging is disabled by default, but when it is enabled, log files are written to a local .modin directory at the same directory level as the notebook/script used to run Modin. See our Logging with Modin documentation for usage information.
Batch Pipeline API#
Modin provides an experimental batched API that pipelines row parallel queries. See our Batch Pipline API Usage Guide for a walkthrough on how to use this feature, as well as Batch Pipeline API documentation for more information about the API.
Fuzzydata Testing#
An experimental GitHub Action on pull request has been added to Modin, which automatically runs the Modin codebase against fuzzydata, a random dataframe workflow generator. The resulting workflow that was used to test Modin codebase can be downloaded as an artifact from the GitHub Actions tab for further inspection. See fuzzydata for more details.