IO Module Description¶
High-Level Data Import Operation Workflow¶
Note
read_csv on pandas backend and Ray engine was taken as an example
in this chapter for reader convenience. For other import functions workflow and
classes/functions naming convension will be the same.
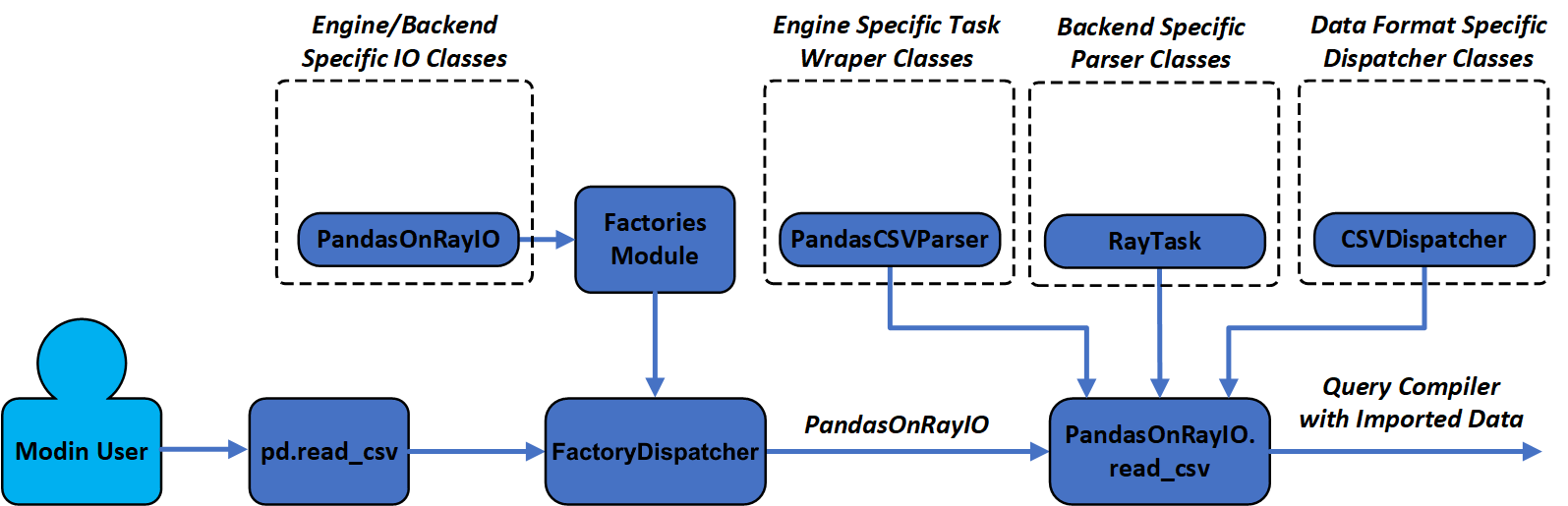
Data import operation workflow diagram is shown below. After user calls high-level
modin.pandas.read_csv function, call is forwarded to the FactoryDispatcher,
which defines which factory from modin.data_management.factories.factories and
backend/engine specific IO class should be used (for Ray engine and pandas backend
IO class will be named PandasOnRayIO). This class defines Modin frame and query
compiler classes and read_* functions, which could be based on the following
classes: RayTask - class for managing remote tasks by concrete distribution
engine, PandasCSVParser - class for data parsing on the workers by specific
backend and CSVDispatcher - class for files handling of concrete file format
including chunking that is executed on the head node.
Dispatcher Classes Workflow Overview¶
Call from read_csv function of PandasOnRayIO class is forwarded to the
_read function of CSVDispatcher class, where function parameters are
preprocessed to check if they are supported (otherwise default pandas implementation
is used) and compute some metadata common for all partitions. Then file is splitted
into chunks (mechanism of splitting is described below) and using this data, tasks
are launched on the remote workers. After remote tasks are finished, additional
results postprocessing is performed, and new query compiler with imported data will
be returned.
Data File Splitting Mechanism¶
Modin file splitting mechanism differs depending on the data format type:
text format type - file is splitted into bytes according user specified needs. In the simplest case, when no row related parameters (such as
nrowsorskiprows) are passed, data chunks limits (start and end bytes) are derived by just roughly dividing the file size by the number of partitions (chunks can slightly differ between each other because usually end byte may occurs inside a line and in that case the last byte of the line should be used instead of initial value). In other cases the same splitting into bytes is used, but chunks sizes are defined according to the number of lines that each partition should contain.columnar store type - file is splitted by even distribution of columns that should be read between chunks.
SQL type - chunking is obtained by wrapping initial SQL query into query that specifies initial row offset and number of rows in the chunk.
After file splitting is complete, chunks data is passed to the parser functions
(PandasCSVParser.parse for read_csv function with pandas backend) for
further processing on each worker.
Submodules Description¶
modin.engines.base.io module is used mostly for storing utils and dispatcher
classes for reading files of different formats.
io.py- class containing basic utils and default implementation of IO functions.file_dispatcher.py- class reading data from different kinds of files and handling some util functions common for all formats. Also this class containsreadfunction which is entry point function for all dispatchers_readfunctions.text - directory for storing all text file format dispatcher classes
text_file_dispatcher.py- class for reading text formats files. This class holdspartitioned_filefunction for splitting text format files into chunks,offsetfunction for moving file offset at the specified amount of bytes,_read_rowsfunction for moving file offset at the specified amount of rows and many other functions.format/feature specific dispatchers:
csv_dispatcher.py,csv_glob_dispatcher.py(reading multiple files simultaneously, experimental feature),excel_dispatcher.py,fwf_dispatcher.pyandjson_dispatcher.py.
column_stores - directory for storing all columnar store file format dispatcher classes
column_store_dispatcher.py- class for reading columnar type files. This class holdsbuild_query_compilerfunction that performs file splitting, deploying remote tasks and results postprocessing and many other functions.format/feature specific dispatchers:
feather_dispatcher.py,hdf_dispatcher.pyandparquet_dispatcher.py.
sql - directory for storing SQL dispatcher class
sql_dispatcher.py- class for reading SQL queries or database tables.