
How does Modin differ from pandas?#
Note
In the earlier tutorials, we have seen how Modin can be used to speed up pandas workflows. Here, we discuss at a high level how Modin works, in particular, how Modin’s dataframe implementation differs from pandas.
Scalablity of implementation#
Modin exposes the pandas API through modin.pandas, but it does not inherit the same pitfalls and design decisions that make it difficult to scale.
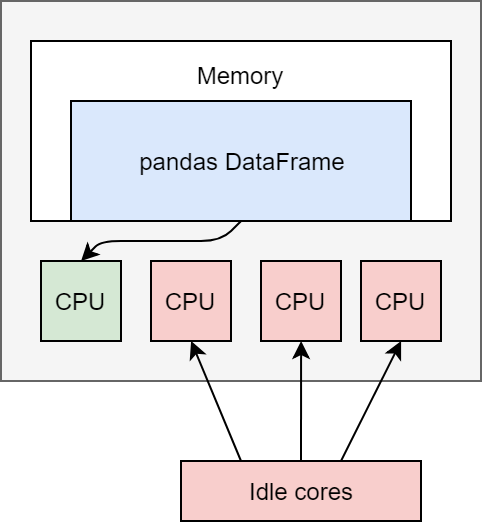
The pandas implementation is inherently single-threaded. This means that only one of
your CPU cores can be utilized at any given time. In a laptop, it would look something
like this with pandas:
However, Modin’s implementation enables you to use all of the cores on your machine, or all of the cores in an entire cluster. On a laptop, it will look something like this:
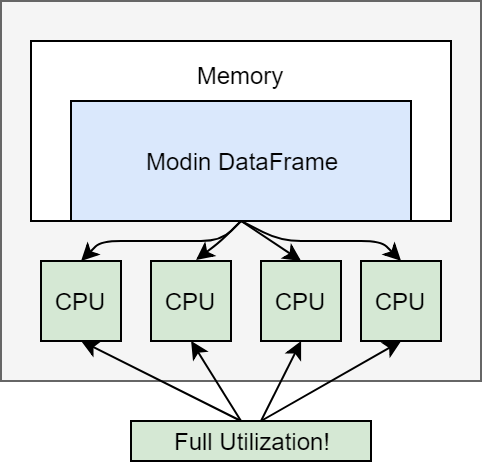
The additional utilization leads to improved performance, however if you want to scale to an entire cluster, Modin suddenly looks something like this:

Modin is able to efficiently make use of all of the hardware available to it!
Memory usage and immutability#
The pandas API contains many cases of “inplace” updates, which are known to be controversial. This is due in part to the way pandas manages memory: the user may think they are saving memory, but pandas is usually copying the data whether an operation was inplace or not.
Modin allows for inplace semantics, but the underlying data structures within Modin’s implementation are immutable, unlike pandas. This immutability gives Modin the ability to internally chain operators and better manage memory layouts, because they will not be changed. This leads to improvements over pandas in memory usage in many common cases, due to the ability to share common memory blocks among all dataframes.
Modin provides the inplace semantics by having a mutable pointer to the immutable internal Modin dataframe. This pointer can change, but the underlying data cannot, so when an inplace update is triggered, Modin will treat it as if it were not inplace and just update the pointer to the resulting Modin dataframe.
API vs implementation#
It is well known that the pandas API contains many duplicate ways of performing the same operation. Modin instead enforces that any one behavior have one and only one implementation internally. This guarantee enables Modin to focus on and optimize a smaller code footprint while still guaranteeing that it covers the entire pandas API. Modin has an internal algebra, which is roughly 15 operators, narrowed down from the original >200 that exist in pandas. The algebra is grounded in both practical and theoretical work. Learn more in our VLDB 2020 paper. More information about this algebra can be found in the architecture documentation.